发布日期:2025-10-29 访问量:
近日,中国人民大学信息学院、数据工程与知识工程教育部重点实验室范举教授团队正式发布了面向数据科学的 Agentic 大模型——DeepAnalyze。该项目旨在推动数据科学从传统的“工具型分析”迈向“智能体驱动分析”的新范式。目前,DeepAnalyze 的模型权重、代码及训练数据已全面开源,相关研究的论文预印本也已同步上传至 Arxiv。欢迎广大研究者与开发者试用。
数据无处不在,如何让人工智能系统自主完成复杂的数据科学任务,一直是智能发展领域的重要目标。传统数据科学工具往往依赖固定流程,只能应对特定的单点任务。DeepAnalyze 则致力于探索数智融合的新一代数据科学系统,从而自主完成复杂的数据科学任务。为实现这一目标,研究团队提出了“课程式 Agentic 训练方法”。该方法模拟人类学习路径,在真实环境中以“从单一能力到复合能力”的方式对大模型进行渐进式训练,逐步提升大模型各项能力。此外,团队还提出了面向数据的轨迹合成框架,自动化构建超过50万条数据科学推理与环境交互数据,在庞大的搜索空间中为大模型提供正确路径的指导。
在功能上,DeepAnalyze能够像数据科学家一样自主完成各项数据科学任务,包括1)全流程数据分析,可自动化完成数据准备、数据分析、建模、可视化与洞察等数据科学全流程;2)数据研究报告生成:在非结构化数据(TXT、Markdown)、半结构化数据(JSON、XML、YAML)、结构化数据(数据库、CSV、Excel)中进行开放式深度研究,生成分析师级别研究报告。
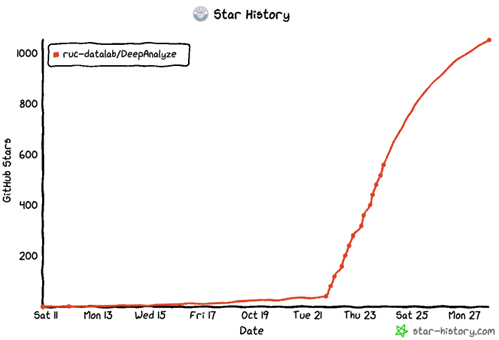
DeepAnalyze发布后在社区内引起了广泛关注。正式发布不到一周,开源项目已在GitHub上获得超过1000个Star,在国内外社交媒体平台累计浏览量超过20万次。欢迎大家试用DeepAnalyze。
项目主页:https://ruc-deepanalyze.github.io
论文链接:https://arxiv.org/pdf/2510.16872
代码仓库:https://github.com/ruc-datalab/DeepAnalyze
模型权重:https://huggingface.co/RUC-DataLab/DeepAnalyze-8B
数据集:https://huggingface.co/datasets/RUC-DataLab/DataScience-Instruct-500K
社区交流:欢迎扫码加入“DeepAnalyze交流讨论群”,参与功能建议、应用分享与协同研发。

成果主要完成人介绍

张绍磊,中国人民大学信息学院青年教师,RUC-DataLab团队骨干。他博士毕业于中国科学院计算技术研究所,导师为冯洋研究员。他的研究方向涵盖大语言模型、多模态大模型、AI for Data Science。相关研究成果在NeurIPS、ACL、ICLR等国际人工智能与自然语言处理会议发表论文30余篇,开源的多语言大模型、多模态大模型、数据科学大模型在GitHub社区累计获得5000+星标。他长期担任CCF-A类国际会议ACL ARR的领域主席和责任编辑。个人主页:zhangshaolei1998@github.io。

范举,中国人民大学教授、博士生导师,国家级青年人才,中国计算机学会数据库专委会、大数据专委会执行委员,RUC-DataLab团队负责人。研究方向包括:数据治理技术与系统、智能数据库系统等。相关研究成果在计算机领域国际顶级期刊/会议发表论文60余篇。作为负责人先后主持国家自然科学基金优秀青年基金项目、重点项目、面上项目,以及多项产学研合作项目。先后获得ICDE 2025 Best Paper Runner-Up、ACM SIGMOD Research Highlight Award、ACM China Rising Award、宝钢优秀教师等奖励。
团队介绍
RUC-DataLab是中国人民大学信息学院、数据工程与知识工程教育部重点实验室设立的科研团队,负责人是范举教授,团队专注于数据系统+人工智能 (Data+AI)交叉领域,致力于将数据技术与人工智能技术深度融合,从而打造更加智能、高效的新型数据系统。主要研究方向包括:(1)数据库系统智能化(AI4DB):利用人工智能技术提升数据库系统的查询性能、自治能力等;(2)数据库技术赋能AI系统(DB4AI):利用数据管理技术支撑大模型训练的数据准备、大模型推理的低延迟、高吞吐优化;(3)数智融合的新型数据科学系统(AI4DS):利用推理大模型、多模态语义理解与智能体等技术,提升数据科学系统的智能化水平与执行性能,有效释放数据价值。